mercredi, 1 avril, 2026
ML/Contextualisation
Le Nexus intègre des modèles de machine learning dont le rôle est précis et délimité : fournir un contexte statistique géochimique aux algorithmes de calcul, pas produire des conclusions. Cette page explique ce que ces modèles font, comment ils s'articulent avec les algorithmes propriétaires d'IsoFind, et comment les utiliser dans un workflow.
Deux niveaux distincts : contextualisation et algorithmes
Avant d'utiliser le ML dans le Nexus, il est important de comprendre la distinction entre les deux couches de calcul qui coexistent dans le système.
Les algorithmes propriétaires d'IsoFind
Les algorithmes d'IsoFind sont des modèles physico-chimiques explicites. Chaque calcul repose sur des équations documentées, des paramètres traçables et des références bibliographiques associées. Pour un processus de fractionnement Rayleigh, l'équation est exposée. Pour une correction de biais de masse, le coefficient est affiché. Pour un calcul d'âge isochronique, les constantes de décroissance utilisées sont identifiables.
Ces algorithmes ne sont pas une boîte noire. Chaque étape du calcul est visible, chaque hypothèse est explicite, et les résultats sont reproductibles indépendamment du logiciel par tout géochimiste disposant des mêmes paramètres.
Les modèles ML de contextualisation
Les modèles ML jouent un rôle différent et complémentaire. Ils ont été entraînés sur 1,7 million de données géochimiques et servent à répondre à une question spécifique : dans quel contexte statistique se situe ce système géochimique par rapport à l'ensemble des situations documentées ?
Concrètement, ils prédisent la spéciation probable d'un élément dans les conditions données (distribution des états d'oxydation, espèces dominantes en solution), et fournissent un niveau de confiance associé. Cette information contextualise les calculs de fractionnement en renseignant sur la chimie de l'élément dans le milieu, sans se substituer aux équations physico-chimiques.
Les modèles ML ne prennent aucune décision scientifique. Ils ne produisent pas d'interprétation de provenance, ne calculent pas d'âge et ne valident pas un workflow. Leur sortie est exclusivement un contexte statistique transmis aux algorithmes, qui l'utilisent comme paramètre d'entrée parmi d'autres.
Architecture technique des modèles
Le système ML du Nexus repose sur deux couches de modèles au format ONNX, déployés localement avec le logiciel.
| Modèle | Rôle | Entrées |
|---|---|---|
| speciation_layer1 | Prédiction de la spéciation de l'élément cible : distribution des états d'oxydation (réduit/oxydé) et des formes dominantes en solution (libre/complexé). | Élément, pH, pe, température, force ionique, concentrations des éléments traces. |
| adsorption_layer2 | Prédiction de la partition adsorption/solution pour les éléments traces sur les phases minérales présentes. | Concentrations des éléments traces, conditions redox, minéralogie de la phase adsorbante. |
Les modèles sont déployés en local avec IsoFind. Aucune donnée n'est envoyée vers un serveur externe lors d'une analyse ML. Le statut de connexion des modèles (disponible ou non) est visible dans le panneau ML du Nexus au démarrage.
Les éléments supportés par les modèles de contextualisation sont les éléments traces géochimiquement actifs : Sb, Fe, Pb, Zn, Cr, Cd, Cu, Sn, Sr, Se. D'autres éléments seront déployés par la suite.
Utiliser le ML dans un workflow
La carte d'analyse
L'analyse ML est déclenchée en ajoutant une carte d'analyse dans le workflow et en la connectant à une signature isotopique et à une carte de conditions. La carte d'analyse est le point de jonction entre le workflow géochimique et le moteur de contextualisation ML.
Bibliothèque
→
Analyse et outils
→
Carte d'analyse
→
Glisser sur le canvas
Pour que l'analyse ML soit possible, la carte d'analyse doit être connectée à au minimum une carte de conditions (pH, pe, température) et une carte de signature isotopique portant l'élément à analyser. Sans carte de conditions, le moteur ML utilise des valeurs par défaut qui peuvent ne pas être représentatives du système étudié.
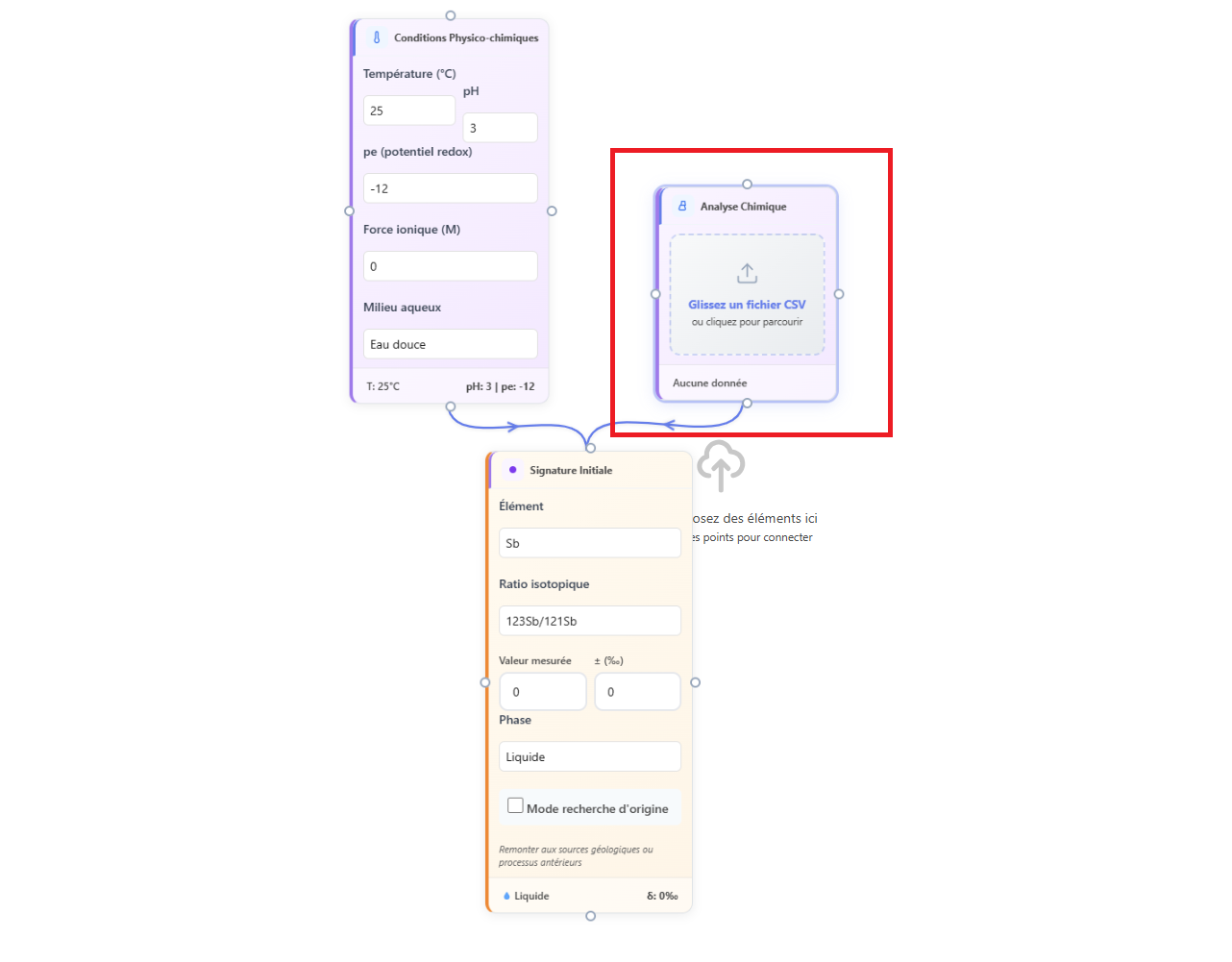 Figure 1 : Carte d'analyse connectée à une signature et à une carte de conditions dans un workflow.
Figure 1 : Carte d'analyse connectée à une signature et à une carte de conditions dans un workflow.
Il n'est pas nécessaire de connecter directement la carte conditions Physico-chimiques à la carte analyse chimique. Les connecter à la même carte suffit et rend le diagramme plus lisible.
Lancer l'analyse
Une fois le workflow structuré avec la carte d'analyse correctement connectée, l'analyse se lance via le bouton Exécuter de la barre d'outils du Nexus. Le moteur parcourt le workflow dans l'ordre des connexions, calcule les fractionnements via les algorithmes physico-chimiques, puis interroge les modèles ML pour obtenir le contexte de spéciation.
Les résultats apparaissent dans le panneau latéral droit du Nexus, dans la section Analyses ML. Chaque analyse est listée avec un badge de confiance coloré indiquant la fiabilité statistique de la prédiction de spéciation.
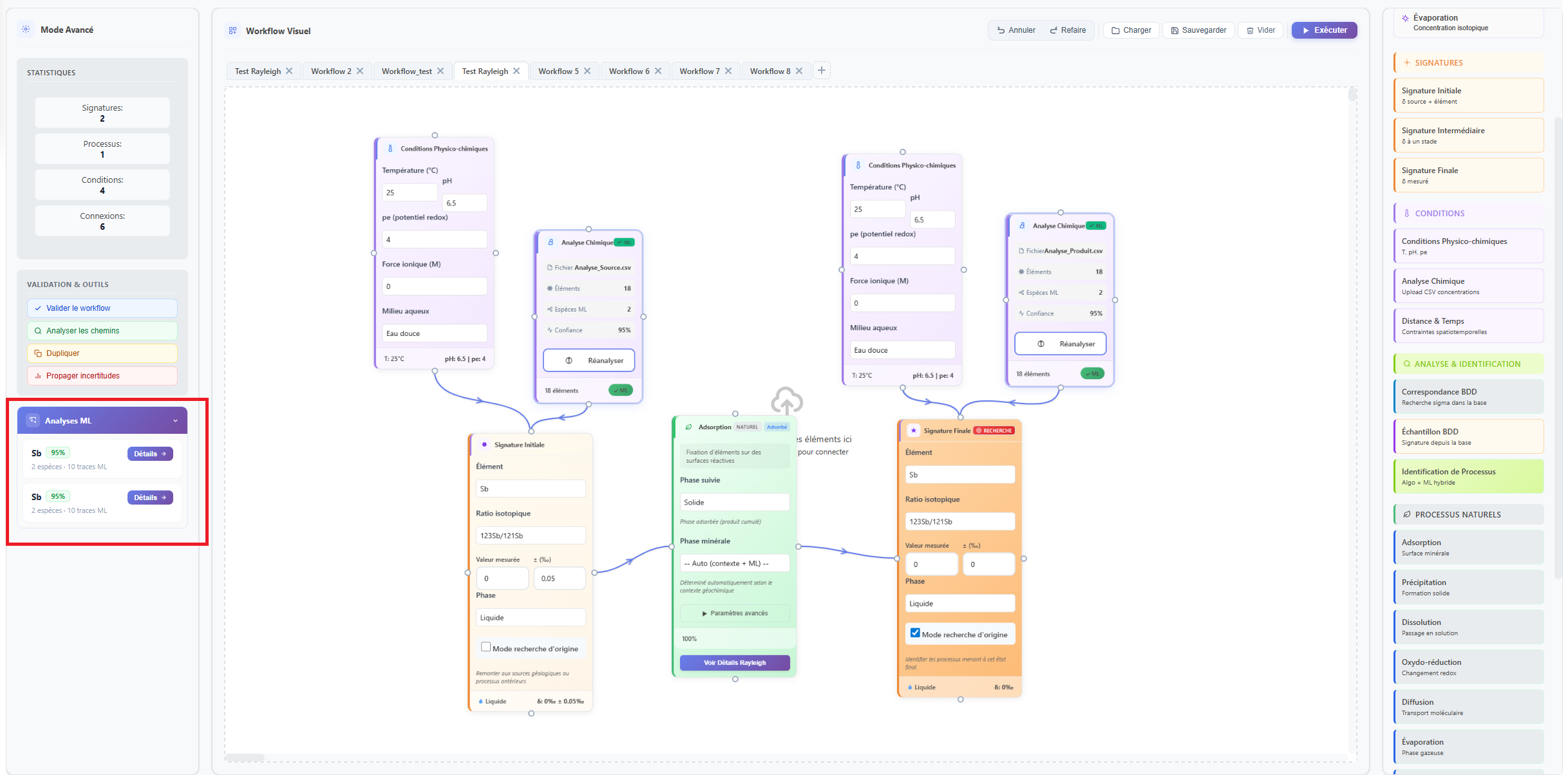 Figure 2 : Le résultat des différentes analyses ML se trouvent sur le côté gauche de l'interface, et sont affichés dans l'ordre d'activation des cartes
Figure 2 : Le résultat des différentes analyses ML se trouvent sur le côté gauche de l'interface, et sont affichés dans l'ordre d'activation des cartes
Lire les résultats de contextualisation
Un clic sur une entrée du panneau ML ouvre la fenêtre de détail. Elle présente les résultats en trois blocs.
Spéciation de l'élément principal
Ce bloc affiche la distribution des états d'oxydation prédits pour l'élément analysé. Pour un élément redox-actif comme Sb, Fe ou Cr, la barre de spéciation montre la proportion de forme réduite (bleue) et oxydée (orange). Pour un élément dont la spéciation principale est la complexation, la barre distingue la forme libre (grise) et la forme complexée (violette).
Le niveau de confiance affiché en haut du bloc indique dans quelle mesure les conditions fournies correspondent à des situations bien documentées dans les données d'entraînement. Un niveau de confiance élevé (vert, au-dessus de 80%) indique que le modèle a rencontré des situations similaires lors de son entraînement. Un niveau faible (rouge, en-dessous de 60%) indique que les conditions sont atypiques par rapport au jeu d'entraînement, et que les prédictions doivent être interprétées avec précaution.
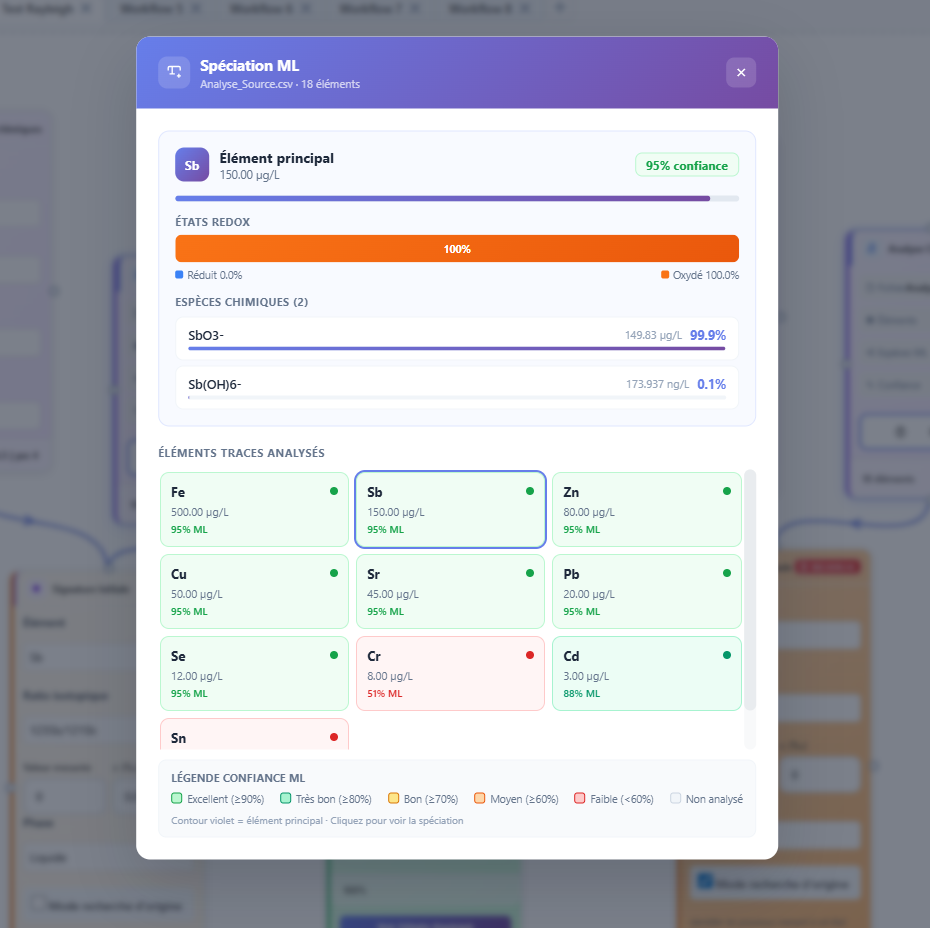 Figure 3 : Résultats de contextualisation ML avec la distribution des états d'oxydation et le niveau de confiance.
Figure 3 : Résultats de contextualisation ML avec la distribution des états d'oxydation et le niveau de confiance.
Espèces en solution
La liste des espèces détaille les formes chimiques dominantes prédites en solution, classées par proportion décroissante. Chaque espèce est accompagnée d'une mini-barre de progression indiquant sa contribution relative à la spéciation totale. Ces informations proviennent directement de la sortie du modèle speciation_layer1.
Grille des éléments traces
La grille affiche l'ensemble des éléments traces analysés en parallèle de l'élément principal. Chaque élément est représenté par un point coloré selon son niveau de confiance ML. L'élément principal du workflow est mis en évidence par un contour distinct. Cette vue permet d'identifier rapidement quels éléments traces se trouvent dans des conditions bien documentées et lesquels sont en dehors du domaine de validité des modèles.
La grille des éléments traces est particulièrement utile pour identifier les co-variations géochimiques significatives. Si plusieurs éléments montrent simultanément un niveau de confiance élevé dans des conditions redox similaires, cela peut indiquer un processus commun de contrôle (adsorption sur un même oxyde de fer, par exemple) cohérent avec les hypothèses du workflow.
Interpréter les niveaux de confiance
| Niveau | Seuil | Signification |
|---|---|---|
| Élevé | Au-dessus de 80% | Les conditions sont bien représentées dans les données d'entraînement. La prédiction de spéciation est statistiquement robuste et peut être utilisée avec confiance pour paramétrer les algorithmes. |
| Modéré | 60% à 80% | Les conditions sont partiellement documentées. La prédiction est plausible mais doit être confrontée aux données de terrain et à la bibliographie spécifique au système étudié. |
| Faible | En-dessous de 60% | Les conditions sont atypiques ou peu documentées dans les données d'entraînement. La prédiction est incertaine. Il est conseillé de s'appuyer sur les valeurs de la bibliothèque de processus plutôt que sur la contextualisation ML. |
Un niveau de confiance faible n'invalide pas l'analyse. Il signale simplement que le modèle ML opère en dehors de son domaine de validité statistique. Dans ce cas, les algorithmes de fractionnement continuent de fonctionner avec les paramètres saisis manuellement dans les cartes, sans utiliser les prédictions ML comme entrée.
Fonctionnement sans modèles ML
Si les fichiers de modèles ONNX ne sont pas présents dans l'installation (version Research sans le module ML, ou installation sans les modèles), le Nexus bascule automatiquement en mode simulation. Dans ce mode, le panneau ML signale l'absence des modèles, et les algorithmes de fractionnement fonctionnent uniquement avec les paramètres explicites des cartes du workflow, sans contextualisation statistique.
Le statut des modèles est consultable à tout moment dans le panneau ML du Nexus. La mention mode: onnx indique que les modèles sont chargés et actifs. La mention mode: simulation indique que le fallback est actif.
Le mode simulation produit des résultats scientifiquement valides pour tous les calculs de fractionnement. La contextualisation ML enrichit ces résultats mais ne les conditionne pas. Un workflow construit et exécuté sans ML reste entièrement exploitable et reproductible.