mercredi, 1 avril, 2026
Intégration Python
IsoFind s'intègre à Python de deux façons complémentaires : via le package open source isof disponible sur PyPI, qui permet de lire et vérifier des fichiers .isof dans n'importe quel script Python indépendamment d'IsoFind, et via l'API REST locale qui permet d'interroger et manipuler la base de données IsoFind directement depuis Python pendant qu'IsoFind est ouvert.
Le package isof (open source)
Package PyPI
Le package isof est un lecteur et vérificateur open source du format ISOF v1.0. Il est indépendant d'IsoFind : n'importe quel script Python peut lire un fichier .isof sans que le logiciel soit installé. Le code source est publié sous licence MIT.
pip install isof
Avec le support pandas (recommandé pour l'analyse de données) :
pip install isof[pandas]
Nécessite Python 3.9 ou supérieur.
Charger un fichier
import isof
# Charger depuis un fichier
report = isof.load("analyse_bolivie.isof")
print(report)
# <ISOfDocument v1.0 — 12 échantillon(s) — IGE Grenoble>
# Charger depuis une chaîne JSON (depuis une API, une base de données...)
with open("analyse.isof") as f:
report = isof.loads(f.read())
Vérifier l'intégrité et l'authenticité
Le format ISOF supporte deux niveaux de signature. Le package vérifie les deux, hors ligne, sans connexion réseau : les certificats IsoFind Root CA et Issuing CA sont embarqués dans le package.
| Niveau | Mécanisme | Garantie |
|---|---|---|
| 1 | Hash SHA-256 sur le contenu | Intégrité : le fichier n'a pas été modifié depuis l'export. |
| 2 | Signature ECDSA P-256 + PKI IsoFind | Authenticité : les données ont été signées par un laboratoire certifié IsoFind. |
# Vérification simple (bool)
if report.is_authentic():
print(f"Données intègres. Signé par : {report.signature.signed_by}")
else:
print("Données altérées ou signature invalide.")
# Résultat détaillé
result = report.verify()
print(result.valid) # bool
print(result.level) # 0 (absente), 1 (SHA-256) ou 2 (ECDSA PKI)
print(result.signer) # organisation ou CN du certificat
print(result.signed_at) # horodatage ISO 8601
print(result.reason) # None si valide, message d'erreur sinon
# Distinguer signature absente et signature corrompue
if result.level == 0:
print("Ce fichier n'est pas signé.")
elif not result.valid:
print(f"Signature présente mais invalide : {result.reason}")
Accéder aux données
# Échantillons
print(len(report.samples))
for sample in report.samples:
print(sample.name, sample.material_type, sample.classification)
# Données isotopiques d'un échantillon
for iso in report.samples[0].isotope_data:
print(iso.element, iso.ratio_name, iso.ratio_value, iso.uncertainty)
# Métadonnées du document
print(report.created_by.organisation)
print(report.created_at)
print(report.project)
# Méthodes documentées dans le fichier
for key, method in report.methods.items():
print(key, method.get("label"))
# Rendements de purification
for key, yield_data in report.purification.items():
print(key, yield_data) # clé : "{sample_id}_{element}"
Export vers pandas et CSV
Le DataFrame produit par to_pandas() est au format "tidy" : une ligne par mesure isotopique, avec les métadonnées de l'échantillon dupliquées sur chaque ligne. Ce format est directement compatible avec matplotlib, seaborn, ou tout autre outil d'analyse.
df = report.to_pandas()
# Colonnes disponibles selon le contenu du fichier
df[["sample_name", "element", "ratio_name", "ratio_value", "ratio_2se"]]
# Filtres standards pandas
pb_data = df[df["element"] == "Pb"]
sources = df[df["classification"] == "source"]
sr_ratio = df[df["ratio_name"] == "87Sr/86Sr"]
# Statistiques rapides
sr_ratio["ratio_value"].describe()
# Export CSV
report.to_csv("export.csv")
# équivalent à : report.to_pandas().to_csv("export.csv", index=False)
Parcourir les étapes d'un pipeline
for sample in report.samples:
pipeline = report.get_pipeline(sample.id)
if pipeline:
print(f"{sample.name} — pipeline : {pipeline.label}")
for stage in pipeline.stages:
print(f" {stage.label} : {stage.status}")
Gestion des erreurs
from isof.exceptions import ISOfParseError, ISOfVersionError, ISOfSignatureError
try:
report = isof.load("fichier.isof")
except ISOfVersionError as e:
# Version du format non supportée par cette version du package
print(f"Version {e.found} non supportée — mettez isof à jour.")
except ISOfParseError as e:
# Fichier JSON invalide ou structure incorrecte
print(f"Fichier invalide : {e}")
except ISOfSignatureError as e:
# Erreur lors de la vérification cryptographique
print(f"Erreur de signature : {e}")
Le package est disponible à pypi.org/project/isof et le code source sur https://github.com/ColinFerrari/isof. Le format ISOF est un standard ouvert : des implémentations tierces dans d'autres langages sont encouragées.
Interroger IsoFind depuis Python via l'API locale
API locale REST
Pendant qu'IsoFind est ouvert, son backend FastAPI est accessible à http://127.0.0.1:8001. Un script Python peut interroger cette API directement avec la bibliothèque requests pour lire des données, créer des échantillons ou déclencher des analyses depuis un notebook Jupyter, un script de traitement ou un pipeline de calcul externe.
pip install requests
Étape préalable : activer l'accès API
Par défaut, l'accès API externe est désactivé dans IsoFind. Avant d'utiliser un script Python, il faut activer l'accès depuis les préférences du logiciel :
Préférences
→
Sécurité
→
Accès API externe
Trois niveaux sont disponibles :
| Mode | Comportement | Usage recommandé |
|---|---|---|
| Désactivé | Aucun script externe ne peut se connecter. /api/local/token retourne 403. | Défaut. À conserver si aucun script externe n'est nécessaire. |
| Accès local sans confirmation | Tout script depuis 127.0.0.1 obtient un token directement, sans popup. | Poste personnel isolé, environnement de confiance totale. |
| Accès avec autorisation manuelle | Chaque nouveau programme déclenche une popup dans IsoFind avec le chemin de l'exécutable. L'utilisateur valide ou refuse. "Se souvenir" enregistre le programme. | Poste partagé, environnement professionnel, usage sensible. |
En mode accès local sans confirmation, tout logiciel malveillant installé sur le poste peut lire et exporter l'intégralité de la base de données. N'activer ce mode que sur un poste dont vous contrôlez entièrement le contenu. En cas de doute, préférer le mode avec autorisation manuelle.
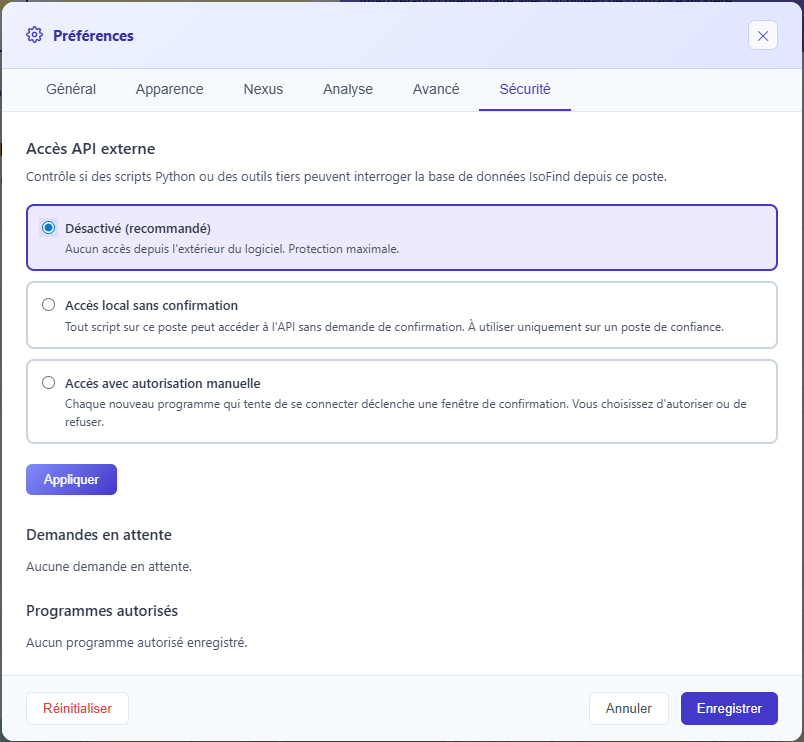 Figure 1 : Onglet Sécurité des préférences avec le sélecteur de mode d'accès API et la liste des programmes autorisés.
Figure 1 : Onglet Sécurité des préférences avec le sélecteur de mode d'accès API et la liste des programmes autorisés.
Obtenir le token de sécurité
Une fois l'accès activé, tout script Python récupère son token via une route dédiée accessible uniquement depuis 127.0.0.1. En mode avec autorisation manuelle, le premier appel attend (jusqu'à 60 secondes) que l'utilisateur valide la popup dans IsoFind.
import requests
BASE = "http://127.0.0.1:8001"
# Le script envoie son PID pour aider IsoFind à identifier l'exécutable
import os
r = requests.get(
f"{BASE}/api/local/token",
headers={"X-Client-PID": str(os.getpid())}
)
# Si le mode est "désactivé", r.status_code == 403
# Si le mode est "autorisation manuelle" et que l'utilisateur n'a pas encore
# répondu, la requête attend jusqu'à 60 secondes
if r.status_code == 403:
err = r.json().get("error", "")
if err == "api_access_disabled":
print("Accès API désactivé. Activez-le dans IsoFind > Préférences > Sécurité.")
elif err == "authorization_denied":
print("Accès refusé par l'utilisateur.")
raise SystemExit(1)
info = r.json()
TOKEN = info.get("token")
HEADERS = {"X-IsoFind-Token": TOKEN} if TOKEN else {}
print(f"Connecté — mode : {info.get('mode', 'dev')}")
En mode autorisation manuelle avec "Se souvenir" coché, le programme est enregistré dans IsoFind. Les exécutions suivantes n'affichent plus de popup : le token est retourné immédiatement. Pour gérer les programmes enregistrés (voir, révoquer), aller dans Préférences > Sécurité > Programmes autorisés.
Un navigateur web malveillant ne peut pas accéder à /api/local/token : le middleware de validation de l'en-tête Host bloque toute requête dont l'hôte n'est pas 127.0.0.1:8001 ou localhost:8001. Un script Python sur le même poste envoie bien Host: 127.0.0.1:8001, il n'est pas affecté.
Vérifier qu'IsoFind est prêt
import requests
BASE = "http://127.0.0.1:8001"
r = requests.get(f"{BASE}/api/ready",
headers=HEADERS)
print(r.json())
# {'status': 'ready'}
Récupérer les échantillons
import requests
import pandas as pd
BASE = "http://127.0.0.1:8001"
# Tous les échantillons
samples = requests.get(f"{BASE}/api/samples",
headers=HEADERS).json()
print(f"{len(samples)} échantillons")
# Avec tri et limite
samples = requests.get(
f"{BASE}/api/samples",
params={"sort": "desc", "limit": 100}
).json()
# Un échantillon précis
s = requests.get(f"{BASE}/api/samples/42",
headers=HEADERS).json()
print(s["name"], s["material_type"])
# Version complète avec méthodes, publications et pipeline
s_full = requests.get(f"{BASE}/api/v2/samples/42/full",
headers=HEADERS).json()
print(s_full["methods"])
Construire un DataFrame depuis la base IsoFind
import requests
import pandas as pd
BASE = "http://127.0.0.1:8001"
# Récupérer toutes les données isotopiques d'un coup
iso_data = requests.get(f"{BASE}/api/samples/isotopic-data",
headers=HEADERS).json()
df = pd.DataFrame(iso_data)
# Colonnes disponibles : sample_id, sample_name, element, ratio_name,
# ratio_value, uncertainty, standard_used, instrument, normalized, ...
print(df.columns.tolist())
# Statistiques par élément
print(df.groupby("element")["ratio_value"].describe())
# Filtrer sur les échantillons normalisés uniquement
df_norm = df[df["normalized"] == True]
Créer un échantillon
r = requests.post(
f"{BASE}/api/samples",
headers=HEADERS,
json={
"name": "BIF-2026-001",
"material_type": "roche",
"sector": "géologie",
"collection_date": "2026-02-15",
"collection_location":"Cerro Rico, Bolivie",
"classification": "source",
"latitude": -19.6078,
"longitude": -65.7527,
"project": "antimony-traceability-2026",
}
)
print(r.status_code, r.json())
Enregistrer des rendements de purification
sample_id = 42
# Enregistrer le rendement Sb pour cet échantillon
r = requests.post(
f"{BASE}/api/samples/{sample_id}/purification-yields",
json={
"element": "Sb",
"yield_percent": 87.3,
"operator": "C. Ferrari",
"method_key": "ion-exchange-sb-v2"
}
)
print(r.json())
# {'success': True, 'sample_id': 42, 'element': 'SB', 'yield_percent': 87.3}
# Lire les rendements enregistrés
yields = requests.get(
f"{BASE}/api/samples/{sample_id}/purification-yields",
headers=HEADERS
).json()
print(yields)
Lancer une recherche de correspondances
# Analyse d'un échantillon déjà en base
r = requests.post(
f"{BASE}/analyze",
headers=HEADERS,
json={
"sample_id": 42,
"threshold": 0.85,
"algorithm": "hybrid",
"classification_filter": "sources",
"same_material": True,
}
)
result = r.json()
print(f"{len(result['matches'])} correspondances")
for match in result["matches"][:5]:
print(f" #{match['rank']} {match['zone_name']} — score {match['overall_score']:.3f}")
# Analyse manuelle sans échantillon en base
r = requests.post(
f"{BASE}/analyze/manual",
headers=HEADERS,
json={
"sample_name": "Inconnu-01",
"material_type":"minerai",
"threshold": 0.75,
"isotope_data": [
{"element": "Sb", "ratio_name": "123Sb/121Sb",
"ratio_value": 0.74738, "uncertainty": 0.00012},
{"element": "Pb", "ratio_name": "206Pb/204Pb",
"ratio_value": 18.421, "uncertainty": 0.003},
]
}
)
print(r.json()["matches"][:3])
Analyse par lots
# Analyser plusieurs échantillons en une seule requête
r = requests.post(
f"{BASE}/api/matching/batch",
json=[1, 2, 3, 42, 57], headers=HEADERS
)
results = r.json()
for sample_id, res in results.items():
if res["status"] == "success":
print(f"ID {sample_id} : {res['matches_count']} correspondances, "
f"meilleure zone = {res['best_zone']} (score {res['best_score']:.3f})")
else:
print(f"ID {sample_id} : erreur — {res['error']}")
Exporter en CSV depuis Python
import requests
# Télécharger le CSV complet de la base
r = requests.get(f"{BASE}/api/samples/export",
headers=HEADERS)
with open("export.csv", "wb") as f:
f.write(r.content)
# Export groupé avec toutes les données associées (méthodes, publications)
r = requests.post(
f"{BASE}/api/v2/samples/export-batch",
json=[1, 2, 3]
)
data = r.json()["data"]
print(f"{data['count']} échantillons exportés le {data['exported_at']}")
Interroger les CRM et les shifts
# Liste des CRM disponibles
crms = requests.get(f"{BASE}/api/crm/list",
headers=HEADERS).json()["data"]
print(f"{len(crms)} CRM en base")
# Calcul du shift pour un CRM donné
r = requests.post(
f"{BASE}/api/shifts/calculate/NIST-3102a",
params={
"element": "Sb",
"isotope_ratio":"123Sb/121Sb"
}
)
shift = r.json()
if shift["success"]:
print(f"Shift calculé : {shift['data']}")
# Convertir une valeur isotopique d'un standard à un autre
r = requests.post(
f"{BASE}/api/shifts/convert",
json={
"value": 0.74738,
"from_std": "NIST-3102a",
"to_std": "IAEA-SbS-1",
"element": "Sb",
"ratio_name": "123Sb/121Sb"
}
)
print(r.json())
La documentation interactive Swagger est disponible à http://127.0.0.1:8001/docs pendant qu'IsoFind est ouvert. Elle liste toutes les routes avec leurs schémas JSON complets et permet de les tester directement depuis le navigateur, utile pour explorer de nouvelles routes avant de les intégrer dans un script.
Combiner les deux approches
Toutes les fonctions auxiliaires définies ci-dessous supposent que BASE et HEADERS sont définis en tête de script via GET /api/local/token. Dans un notebook Jupyter, exécuter la cellule d'initialisation une seule fois en début de session.
Le workflow le plus puissant combine l'API locale (pour accéder aux données de la base IsoFind en direct) et le package isof (pour lire et vérifier les fichiers exportés). Exemple complet : exporter un ensemble d'échantillons depuis IsoFind, signer le fichier ISOF résultant et le vérifier programmatiquement.
import requests
import isof
import pandas as pd
BASE = "http://127.0.0.1:8001"
# 1. Récupérer les échantillons depuis la base IsoFind
iso_data = requests.get(f"{BASE}/api/samples/isotopic-data",
headers=HEADERS).json()
df = pd.DataFrame(iso_data)
# 2. Analyser : moyennes par élément et par matériau
pivot = df.pivot_table(
values="ratio_value",
index="sample_material_type",
columns="element",
aggfunc="mean"
)
print(pivot)
# 3. Charger et vérifier un fichier ISOF exporté par IsoFind
report = isof.load("export_certifie.isof")
result = report.verify()
if result.valid and result.level == 2:
print(f"Certifié par : {result.signer}")
print(f"Signé le : {result.signed_at}")
df_certified = report.to_pandas()
else:
raise ValueError(f"Signature invalide : {result.reason}")
Console Python intégrée dans IsoFind
Console Pyodide
En plus des deux approches ci-dessus, IsoFind intègre une console Python interactive qui s'exécute directement dans le logiciel, sans installation. Elle est propulsée par Pyodide (Python 3.11 compilé en WebAssembly) et donne accès aux données de la base courante via des variables et fonctions prêtes à l'emploi.
La console est accessible depuis :
Menu Outils
→
Console Python
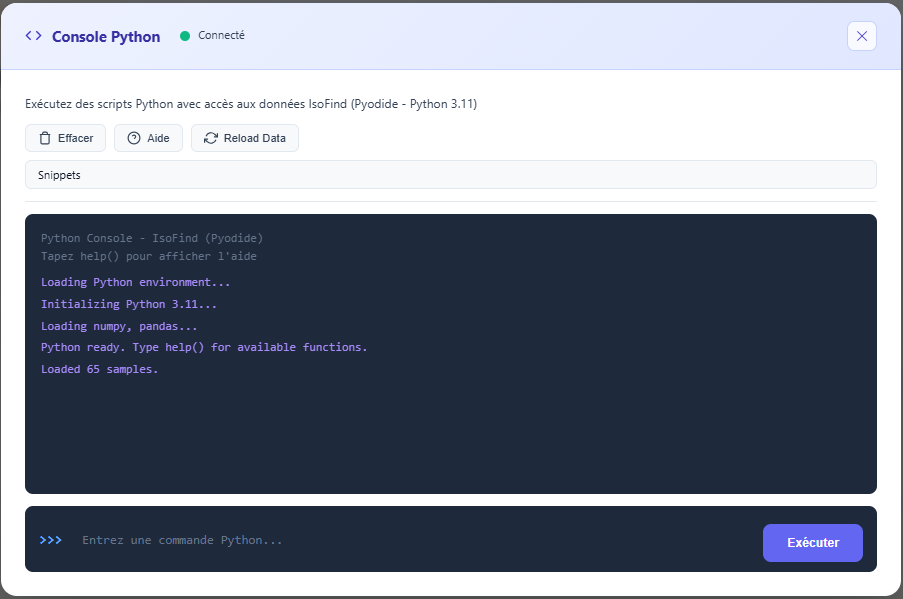 Figure 2 : Console Python IsoFind avec les données de la base chargées automatiquement.
Figure 2 : Console Python IsoFind avec les données de la base chargées automatiquement.
Variables disponibles automatiquement
# Chargées au démarrage depuis /api/samples
samples # list[dict] : tous les échantillons de la base
isotopes # dict : données isotopiques indexées par nom d'échantillon
Fonctions utilitaires pré-définies
# Accès par identifiant ou par nom
s = get_sample(42)
s = get_sample_by_name("BIF-2026-001")
iso = get_isotopes("BIF-2026-001")
# Conversion en DataFrame pandas (une ligne par mesure isotopique)
df = to_dataframe()
print(df.head())
# Statistiques pour un ratio isotopique
isotope_stats("87Sr/86Sr")
Statistics for 87Sr/86Sr:
Count: 42
Mean: 0.710341
Std: 0.002187
Min: 0.706012
Max: 0.715892
Median: 0.710215
Bibliothèques disponibles
import numpy as np
import pandas as pd
# Exemple : distribution des valeurs 87Sr/86Sr
vals = [
iso.get("ratio_value")
for s in samples
for iso in (s.get("isotope_data") or [])
if iso.get("ratio_name") == "87Sr/86Sr"
and iso.get("ratio_value") is not None
]
arr = np.array(vals, dtype=float)
print(f"n={len(arr)}, mean={arr.mean():.6f}, std={arr.std():.6f}")
# Exemple : filtrage et tri avec pandas
df = to_dataframe()
roches = df[df["material_type"] == "roche"].sort_values("87Sr/86Sr")
print(roches[["name", "87Sr/86Sr", "87Sr/86Sr_err"]])
Matplotlib n'est pas disponible dans la console Pyodide (pas de rendu graphique dans l'environnement navigateur). Pour des visualisations, utiliser df.describe() et isotope_stats() pour les statistiques, ou exporter les données et les tracer dans un script Python externe.
Récapitulatif des trois approches
| Approche | Quand l'utiliser | IsoFind requis | Installation |
|---|---|---|---|
| Package isof (PyPI) | Lire et vérifier des fichiers .isof dans n'importe quel script ou pipeline, indépendamment d'IsoFind. Partager des données vérifiables avec des tiers. | Non | pip install isof |
| API locale (requests) | Accéder à la base IsoFind en direct, créer des échantillons, déclencher des analyses depuis un notebook Jupyter ou un script de traitement externe. Nécessite d'activer l'accès dans Préférences > Sécurité. | Oui (ouvert) | pip install requests |
| Console Pyodide intégrée | Exploration rapide, calculs ad hoc, statistiques sur la base courante. Pas d'installation, directement dans IsoFind. | Oui (ouvert) | Aucune |